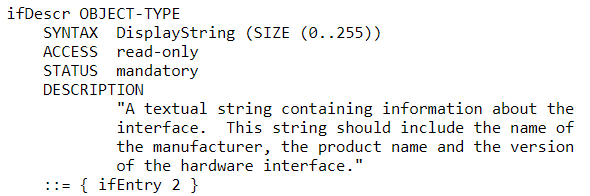
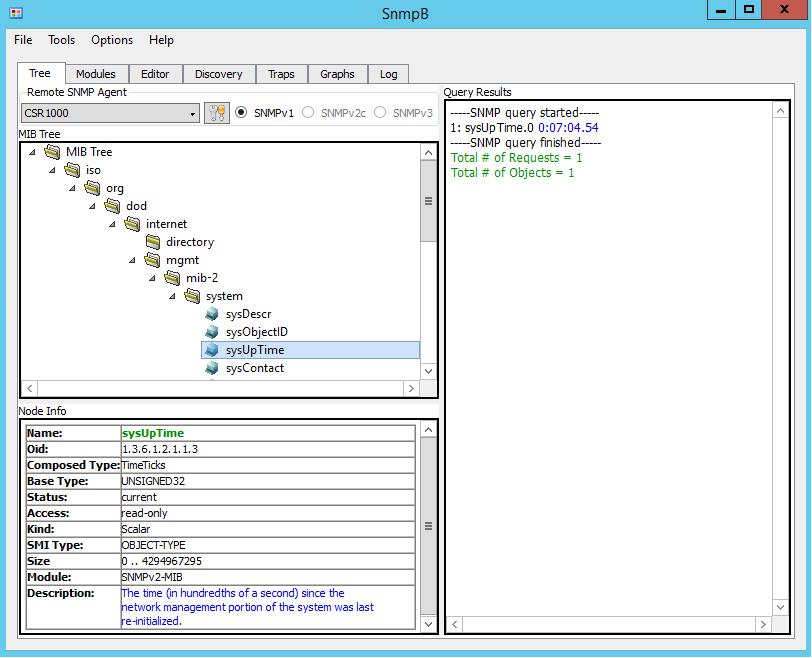
This is part 1 in the vSphere ESXi Networking Guide series which will cover theory, operation, and configuration for different components of vSphere Networking.
Virtual machines need to communicate with each other within an ESXi host and with other nodes reachable over the network. A virtual switch is a software component that enables this communication. vSphere can use Standard Switches (VSS) or Distributed Switches (VDS). vSphere Standard Switch is available with any license tier or edition of vSphere and it is the topic of this article.
ESXi hosts and vSwitches
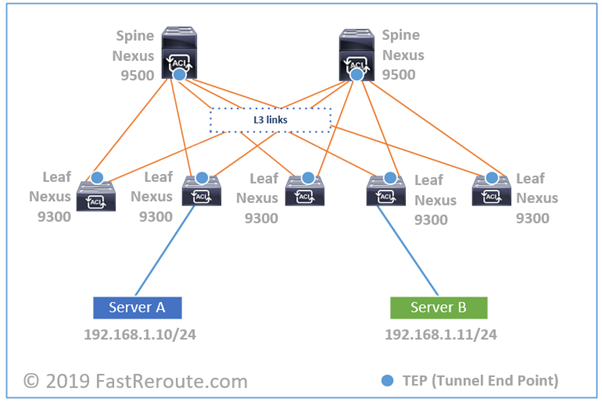
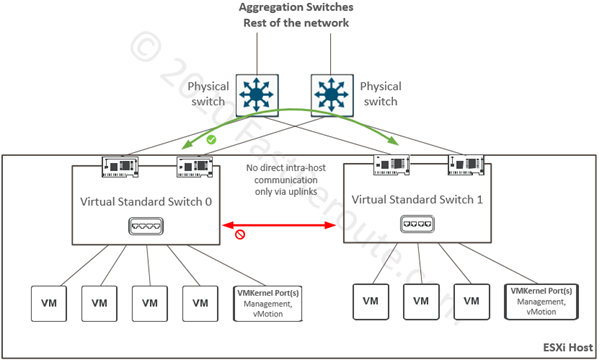
An ESXi host can contain one or multiple standard virtual switches. By default, a virtual standard switch is created during the host installation which provides default VM network and management access to the host itself. It is also possible to delete all standard switches from an ESXi host and use distributed switches instead.
Each virtual switch is isolated from other virtual switches on the same host. In the diagram below, a VM on Switch0 will not be able to reach another VM connected to Switch1 directly within the host. It is possible, however, for them to communicate via upstream physical switches if the required VLAN and interface configuration is in place.
Each vSwitch also has a dedicated uplink or multiple uplinks allocated to it. In cases where no external communication is required, vSwitch can operate without uplinks.
IP-based traffic is often segregated with the use of dedicated physical network adapters which can be connected to a separate set of switches. In such scenarios, storage-related uplinks and corresponding VMKernel ports can be placed into a separate vSwitch.
Other use cases for creating additional vSwitches include:
- Separation of Dev/Test environments from the production systems
- Security-related isolation, for example, placing uplinks to a dedicated physical switch for DMZ virtual machines
Port groups
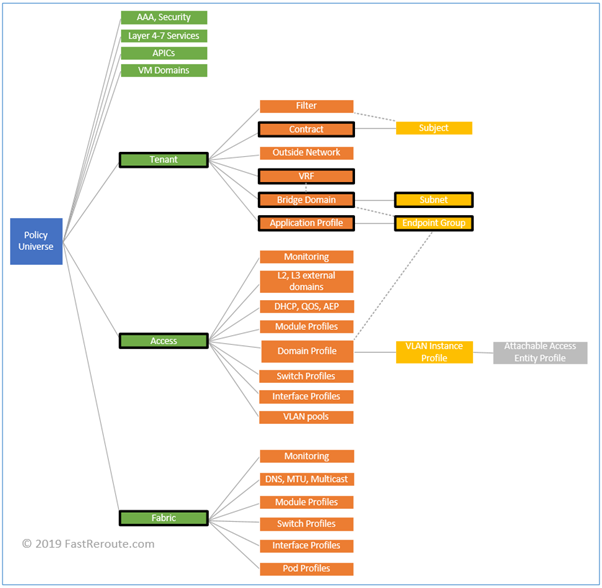
Single virtual switch can contain one or multiple port groups, or no port groups at all. Each port group can either contain one or multiple VM-facing ports or it can contain a single VMKernel port. Refer to the diagram below, which illustrates the relationship between port groups and their members.
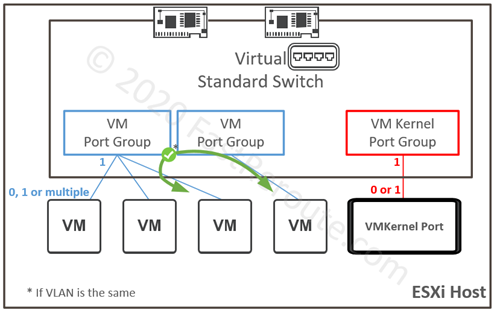
Port groups can be and usually are mapped to different VLANs. However, multiple port groups can be mapped to the same VLAN, in which case they don’t provide isolation and ports can communicate directly within the host. Note the difference to vSwitch operation that prevents direct connectivity within the host.
A port group, as its name suggests, aggregates ports with similar configuration requirements, including VLAN membership, security parameters, traffic shaping, and uplink selection policies.
VLANs
VLAN or Virtual LAN concept originates from physical Ethernet switching as a way to split a single switch into multiple isolated groups of ports. Each of such groups is the same Layer 2 or broadcast domain, which means that hosts connected to the same group can send each other Layer 2 frames directly without involving Layer 3 device, such as a router. VLAN usually represents a single IPv4 subnet.
End-user device-facing ports can be assigned to a single VLAN, in this case, they are called access ports. Upstream or another switch-facing port can also be allocated to a single VLAN, however, this requires additional port for every VLAN that has members behind the upstream switch.
A more efficient way is to add additional information to each frame called 802.1q tag, so multiple VLANs can be transmitted over a single interface. Interface that carries traffic for multiple VLANs using tags is called 802.1q trunk port.
One of the VLANs can be designated as native for an 802.1q trunk. Switch will not add a tag to the native VLAN frames. As a result, if an end device is not using tagging, it will still be able to process frames in the native VLAN.
It is also possible to configure a port connected to a server as an 802.1q trunk. The operating system driver can then present the trunk as multiple virtual adapters, each in the corresponding VLAN.
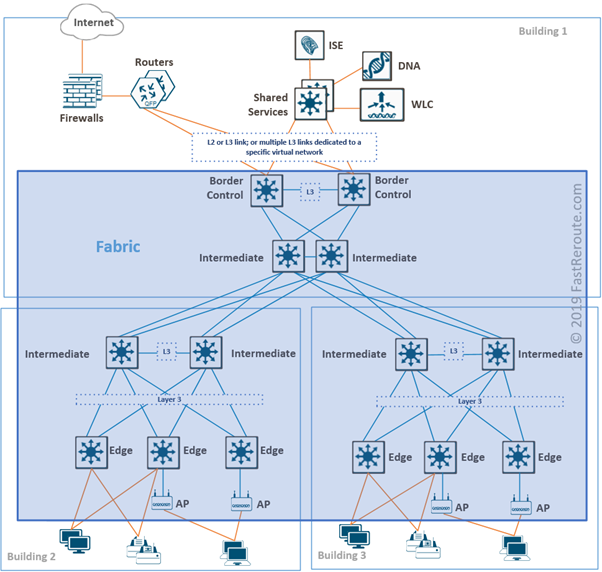
How VLANs are mapped to different virtual switches components?
A virtual switch is designed to operate in a similar way as its physical equivalent. Uplinks are network interface cards of an ESXi host. No special configuration is required on uplinks to enable 802.1q tagging. VLANs are defined on a port-group level and tagging is automatically enabled on uplinks. Upstream switch must have relevant configuration to enable tagging towards the switch.
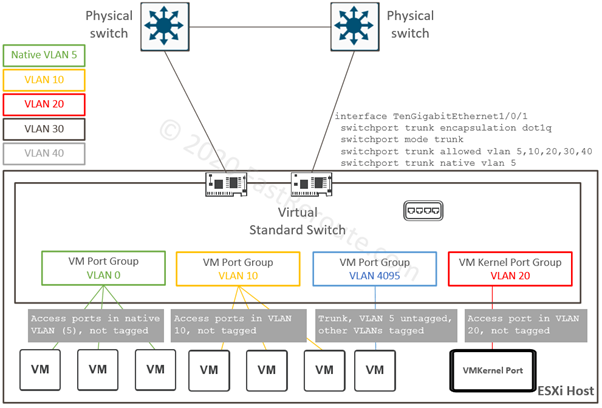
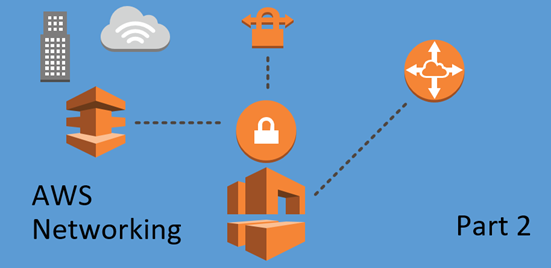
Consider sample topology shown in Figure 3. Physical switches have 5 VLANs defined and have the same configuration on their downstream ports connected to a single ESXi host. Cisco Catalyst syntax is provided in this example.
Frames on these physical links will be tagged with VLAN IDs of 10, 20, 30 and 40. VLAN ID 5 is the exception, as it is a native VLAN on the trunk. Frames of this VLAN will be sent without a tag from the physical switch to the virtual switch.
Virtual standard switch has 4 port groups defined – 3 for VM communication and one VMKernel port group. When Yellow VLAN 10 or Red VLAN 20 (or any VLAN ID in the range of 1 to 4094) is allocated to a port group, the virtual switch strips tag when delivering it to VM or VMKernel port in this group. It is similar to how access ports operate on a physical switch.
Green VLAN 0 is a special case. This port group will get all untagged frames received on uplinks. In the example shown in figure 3, the green port group will effectively be in VLAN 5, as it is designated as native by the upstream switch. VM adapters connected to this port group will also receive untagged frames. To avoid confusion when determining VLAN ID of a port group uses explicit VLAN tagging for all port groups. Designate one of the not-in-use VLANs as native on physical switch interfaces. It is inline with security recommendations for physical inter-switch communication to prevent so-called VLAN-hopping attacks.
The VLAN ID of 4095, when allocated to the port group, tells that tags must not be stripped and delivered to VM’s guest OS to process. Ports in this port group are 802.1q trunks with native VLAN 5. Its frames will be sent without a tag to a VMs.
Virtual Machines interfaces and VMKernel ports
A virtual machine uses one or multiple adapters to connect to port groups. Virtual Machine facing ports are Layer 2, so no IP addresses need to be specified on ESXi host. Router for VMs will be outside of ESXi host with the exception of virtual software routers or firewalls.
Guest OS requires a NIC driver, as it would with a physical adapter. Currently, there are 2 types of adapters available with ESXi: E1000 and VMXNET 3. E1000 emulates Intel network card and guest OS usually has a driver for it included in a standard set of drivers. VMXNET 3, also known as para-virtual adapter, provides better performance and more features. Drivers for VMXNET 3 are available with VMWare tools.
VMKernel port provides connectivity to the ESXi host itself. Each VMKernel port requires a dedicated port group. VMKernel port is layer 3 port with IP address assigned, however, multiple VMKernel ports can share the same VLAN.
During installation, a default management VMKernel port is automatically created. Additional ports can be created for the following types of host-sourced traffic:
- iSCSI or NFS
- vMotion
- Provisioning
- Fault Tolerance logging
- vSphere Replication
- vSphere Replication NFC
- vSAN
VMKernel also associates with a TCP/IP stack. Each stack has a separate IP routing table and DNS configuration. Different types of management traffic can use its own default gateway instead of adding multiple static routes with a single stack.
vSwitch and Port Group policies
There are 3 categories of settings that can be applied to Port Groups. While the settings can also be defined on a vSwitch level, they are ultimately applied to Port Groups.
- Uplink configuration (NIC teaming)
- Security
- Traffic shaping
We will discuss each of these categories in the following section. By default, all port groups inherit global configuration applied on vSwitch, which serves as a template for a default set of settings. If a specific port group requires different policy settings, an administrator can override vSwitch settings on a port group level.
Uplink configuration settings
NIC teaming settings define how traffic will be distributed across multiple network adapters. Before discussing the uplink configuration further, I will provide a short overview of how multiple uplinks can be active at the same time without creating a layer 2 loop.
How Virtual Standard Switch prevents loops? In figure 3 two network adapters create a loop, as the physical switches are inter-connected directly upstream. You might be wondering if the switches recognize that there is a loop and if they need to block any of the interfaces using spanning tree protocol, as it would be done in a traditional switched network. Virtual Standard Switches don’t run STP. They also do not forward BPDUs received from one upstream switch to another.
To prevent consequences of Layer 2 loops, such as broadcast storms, a virtual switch uses a simple rule of not forwarding traffic received from one uplink to any other uplink. This way every frame’s source or destination address must always be either a VM or a VMKernel port. With this rule in place, all physical interfaces can forward traffic at the same time. Upstream switch ports can be configured as edge ports or using features such as portfast, which disables STP on the port.
Note that nothing stops a VM perform “inside-OS” Layer 2 bridging between its adapters which are pinned to different uplinks. This case doesn’t fall under the rule above, as from hypervisor perspective traffic goes to and from a VM. Such configuration can bring the network down or significantly degrade its performance due to the Layer 2 loop created.
Now we have discussed how multiple adapters can be active at the same time, let’s discuss different types of load balancing of traffic across these uplinks.
There are several load-balancing mechanisms available under NIC teaming configuration of a port group:
- Originating port ID
- Source MAC hash
- IP hash
Diagram 4 shows 2 standard switches with each port group configured to use one of the algorithms above.
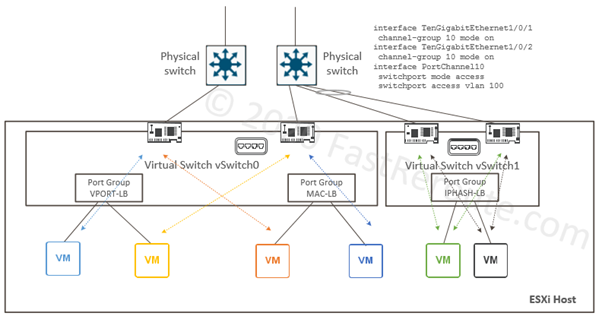
Virtual port- and source MAC-based
Virtual port-based balancing is the default algorithm, which assigns a virtual port to a specific uplink interface. This way if there are 8 VM ports and 2 uplinks, 4 VM ports will be mapped to one uplink and other four to another.
MAC-based load-balancing algorithm is similar to virtual port-based with the difference of input for the algorithm is not a virtual port ID, but VM’s source MAC address.
As different VMs can generate different loads but will have the same weight, these two algorithms cannot evenly utilize available upstream interface bandwidth as a downside. The benefit of these load balancing methods is that they are simple to troubleshoot and will work with any upstream switch configuration, as a VM MAC address will be consistently reachable via a single physical interface.
IP hash-based
This algorithm is based on selecting uplink based on a combination of source and destination IP address of a packet. This provides even uplink utilization, as in this scenario traffic from every single VM will be split across many uplinks if it communicates with multiple devices. With this load balancing configuration, the upstream switches must have a specific configuration for the reason below.
A physical switch learns source MAC addresses as part of its operation. When traffic from a single source MAC address is seen over more than one interface, the switch has to rapidly invalidate and update its MAC table. In some cases, switches can block offending ports, as MAC flapping is also a sign of a Layer 2 loop.
The solution to this is to configure the upstream switch as static EtherChannel (or Link Aggregation Group). It has to be static configuration, as shown in the configuration example of figure 4, as LACP is not supported on Standard Switches. If there are multiple upstream switches they must be either physically stacked together or employ some virtual form of stacking, such as Cisco Nexus VPC or Catalyst VSS/Virtual StackWise.
Failover settings
If no load balancing is required for the port group select “Use Explicit Failover Order” listed as one of the available load balancing methods in the configuration menu. This setting essentially saying do not use load balancing, but just failover to another active adapter if the active one fails.
Failover order is managed by placing adapters in one of three categories:
- Active adapters. To use load balancing mechanisms described above, place at least 2 adapters to this list.
- Standby adapters. Adapter in this category replaces failed active adapters.
- Unused adapters. Prevents specific port groups from using particular adapters.
To identify if the adapter went down ESXi host by default will check its link status. This will not detect upstream switch failures and the host might be sending traffic to black hole over the failed link. An administrator can change the failure detection method to be beacon-probe based. When it is enabled, the host will send broadcast beacon that must be received via multiple NICs in the same team. It is recommended to have at least 3 physical adapters connected to different switches.
Security settings
Each port group has 3 parameters controlling layer 2 security:
- Promiscuous mode
- MAC address changes
- Forged transmits
Promiscuous mode
Ports in a port group that has Accept action for promiscuous mode will receive a copy of all traffic in the VSwitch that port group is in. It is similar to the port mirroring feature available in physical switches. By default, this setting is set to Reject.
This setting should be enabled with care and only when required, for example, to support different appliances that work with a copy of the traffic for security and monitoring analysis. In such cases, create a dedicated port group and override default behavior on it by enabling Promiscuous mode. Enabling this setting on the switch level or on the port group which contains other VM ports is a security risk, as VMs can run Wireshark or similar tools to intercept traffic exchanged by other VMs.
MAC address changes
The hypervisor assigns a virtual MAC address to a VM. Guest OS can try to change this MAC address, however, with this setting set to Reject, no packets will be sent to Guest VM’s new MAC address. This setting works for the traffic in the direction towards VM. By default, this setting is set to Accept when a switch is created via vCenter and to Reject when created directly via ESXi host.
Forged transmits
Mirrored version of the previous setting which checks frames as they are received from VM. If the source MAC address doesn’t match the one that was assigned by ESXi host, such a frame will be discarded. This setting has similar defaults as the previous setting.
Traffic shaping
The final set of settings we will discuss in this article is related to traffic shaping which is a mechanism to limit the throughput of traffic to a specified value. Standard Virtual Switches support only outbound traffic shaping, i.e. virtual machine’s upload. When it is enabled you have access to 3 parameters:
- Average Bandwidth (bits per seconds)
- Peak Bandwidth (bits per seconds)
- Burst Size (bytes)
Average Bandwidth defines the target rate over a period of time. Many applications send traffic in non-uniform pattern and there will be quiet periods followed by short bursts. By configuring Burst Size you allow the algorithm to accumulate bonus credit for quite periods which then can be used to send at rates higher than average, up to peak bandwidth.
The settings are applied to each port, i.e. values are not aggregate numbers for all ports.
In the next article, I will provide information on how to perform the configuration of concepts described in this post.